 |
4000156919 |
|
4000156919 |
来源:巨灵鸟软件 作者:进销存软件 发布:2017/5/11 浏览次数:6096
端到端时代
语音识别的端到端方法主要是代价函数发生了变化,但神经网络的模型结构并没有太大变化。总体来说,端到端技术解决了输入序列的长度远大于输出序列长度的问题。端到端技术主要分成两类:一类是 CTC 方法,另一类是 Sequence-to-Sequence 方法。传统语音识别 DNN-HMM 架构里的声学模型,每一帧输入都对应一个标签类别,标签需要反复的迭代来确保对齐更准确。
采用 CTC 作为损失函数的声学模型序列,不需要预先对数据对齐,只需要一个输入序列和一个输出序列就可以进行训练。CTC 关心的是预测输出的序列是否和真实的序列相近,而不关心预测输出序列中每个结果在时间点上是否和输入的序列正好对齐。CTC 建模单元是音素或者字,因此它引入了 Blank。对于一段语音,CTC 最后输出的是尖峰的序列,尖峰的位置对应建模单元的 Label,其他位置都是 Blank。
Sequence-to-Sequence 方法原来主要应用于机器翻译领域。2017 年,Google 将其应用于语音识别领域,取得了非常好的效果,将词错误率降低至5.6%。如下图所示,Google 提出新系统的框架由三个部分组成:Encoder 编码器组件,它和标准的声学模型相似,输入的是语音信号的时频特征;经过一系列神经网络,映射成高级特征 henc,然后传递给 Attention 组件,其使用 henc 特征学习输入 x 和预测子单元之间的对齐方式,子单元可以是一个音素或一个字。最后,attention 模块的输出传递给 Decoder,生成一系列假设词的概率分布,类似于传统的语言模型。
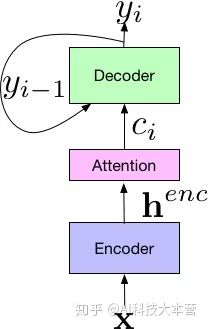
端到端技术的突破,不再需要 HMM 来描述音素内部状态的变化,而是将语音识别的所有模块统一成神经网络模型,使语音识别朝着更简单、更高效、更准确的方向发展。
语音识别的技术现状
目前,主流语音识别框架还是由 3 个部分组成:声学模型、语言模型和解码器,有些框架也包括前端处理和后处理。随着各种深度神经网络以及端到端技术的兴起,声学模型是近几年非常热门的方向,业界都纷纷发布自己新的声学模型结构,刷新各个数据库的识别记录。由于中文语音识别的复杂性,国内在声学模型的研究进展相对更快一些,主流方向是更深更复杂的神经网络技术融合端到端技术。
2018年,科大讯飞提出深度全序列卷积神经网络(DFCNN),DFCNN 使用大量的卷积直接对整句语音信号进行建模,主要借鉴了图像识别的网络配置,每个卷积层使用小卷积核,并在多个卷积层之后再加上池化层,通过累积非常多卷积池化层对,从而可以看到更多的历史信息。
2018年,阿里提出 LFR-DFSMN(Lower Frame Rate-Deep Feedforward Sequential Memory Networks)。该模型将低帧率算法和 DFSMN 算法进行融合,语音识别错误率相比上一代技术降低 20%,解码速度提升 3 倍。FSMN 通过在 FNN 的隐层添加一些可学习的记忆模块,从而可以有效的对语音的长时相关性进行建模。而 DFSMN 是通过跳转避免深层网络的梯度消失问题,可以训练出更深层的网络结构。
2019 年,百度提出了流式多级的截断注意力模型 SMLTA,该模型是在 LSTM 和 CTC 的基础上引入了注意力机制来获取更大范围和更有层次的上下文信息。其中流式表示可以直接对语音进行一个小片段一个小片段的增量解码;多级表示堆叠多层注意力模型;截断则表示利用 CTC 模型的尖峰信息,把语音切割成一个一个小片段,注意力模型和解码可以在这些小片段上展开。在线语音识别率上,该模型比百度上一代 Deep Peak2 模型提升相对 15% 的性能。
开源语音识别 Kaldi 是业界语音识别框架的基石。Kaldi 的作者 Daniel Povey 一直推崇的是 Chain 模型。该模型是一种类似于 CTC 的技术,建模单元相比于传统的状态要更粗颗粒一些,只有两个状态,一个状态是 CD Phone,另一个是 CD Phone 的空白,训练方法采用的是 Lattice-Free MMI 训练。该模型结构可以采用低帧率的方式进行解码,解码帧率为传统神经网络声学模型的三分之一,而准确率相比于传统模型有非常显著的提升。
远场语音识别技术主要解决真实场景下舒适距离内人机任务对话和服务的问题,是 2015 年以后开始兴起的技术。由于远场语音识别解决了复杂环境下的识别问题,在智能家居、智能汽车、智能会议、智能安防等实际场景中获得了广泛应用。目前国内远场语音识别的技术框架以前端信号处理和后端语音识别为主,前端利用麦克风阵列做去混响、波束形成等信号处理,以让语音更清晰,然后送入后端的语音识别引擎进行识别。
语音识别另外两个技术部分:语言模型和解码器,目前来看并没有太大的技术变化。语言模型主流还是基于传统的 N-Gram 方法,虽然目前也有神经网络的语言模型的研究,但在实用中主要还是更多用于后处理纠错。解码器的核心指标是速度,业界大部分都是按照静态解码的方式进行,即将声学模型和语言模型构造成 WFST 网络,该网络包含了所有可能路径,解码就是在该空间进行搜索的过程。由于该理论相对成熟,更多的是工程优化的问题,所以不论是学术还是产业目前关注的较少。
语音识别的技术趋势
语音识别主要趋于远场化和融合化的方向发展,但在远场可靠性还有很多难点没有突破,比如多轮交互、多人噪杂等场景还有待突破,还有需求较为迫切的人声分离等技术。新的技术应该彻底解决这些问题,让机器听觉远超人类的感知能力。这不能仅仅只是算法的进步,需要整个产业链的共同技术升级,包括更为先进的传感器和算力更强的芯片。
单从远场语音识别技术来看,仍然存在很多挑战,包括:
(1)回声消除技术。由于喇叭非线性失真的存在,单纯依靠信号处理手段很难将回声消除干净,这也阻碍了语音交互系统的推广,现有的基于深度学习的回声消除技术都没有考虑相位信息,直接求取的是各个频带上的增益,能否利用深度学习将非线性失真进行拟合,同时结合信号处理手段可能是一个好的方向。
(2)噪声下的语音识别仍有待突破。信号处理擅长处理线性问题,深度学习擅长处理非线性问题,而实际问题一定是线性和非线性的叠加,因此一定是两者融合才有可能更好地解决噪声下的语音识别问题。
(3)上述两个问题的共性是目前的深度学习仅用到了语音信号各个频带的能量信息,而忽略了语音信号的相位信息,尤其是对于多通道而言,如何让深度学习更好的利用相位信息可能是未来的一个方向。
(4)另外,在较少数据量的情况下,如何通过迁移学习得到一个好的声学模型也是研究的热点方向。例如方言识别,若有一个比较好的普通话声学模型,如何利用少量的方言数据得到一个好的方言声学模型,如果做到这点将极大扩展语音识别的应用范畴。这方面已经取得了一些进展,但更多的是一些训练技巧,距离终极目标还有一定差距。
(5)语音识别的目的是让机器可以理解人类,因此转换成文字并不是最终的目的。如何将语音识别和语义理解结合起来可能是未来更为重要的一个方向。语音识别里的 LSTM 已经考虑了语音的历史时刻信息,但语义理解需要更多的历史信息才能有帮助,因此如何将更多上下文会话信息传递给语音识别引擎是一个难题。
(6)让机器听懂人类语言,仅靠声音信息还不够,“声光电热力磁”这些物理传感手段,下一步必然都要融合在一起,只有这样机器才能感知世界的真实信息,这是机器能够学习人类知识的前提条件。而且,机器必然要超越人类的五官,能够看到人类看不到的世界,听到人类听不到的世界。
来源:巨灵鸟 欢迎分享本文
上一个文章:技术一旦被用来作恶,究竟会有多可怕(一)
下一个文章:语音识别技术简史(三)